Ансамбли в машинном обучении
Представим, что у вас есть несколько моделей, обученных на ваших данных. Можно ли придумать процедуру, которая позволит использовать все имеющиеся модели и при этом получить на тестовых данных качество выше, чем могла показать каждая из этих моделей в отдельности?
Некоторые картинки в тексте кликабельны. Это означает, что они были заимствованы из какого-то источника, и при клике вы сможете перейти к этому источнику.
Смещение и разброс
Предположим, что мы решаем задачу регрессии с квадратичной функцией потерь. При использовании квадратичной функции потерь для оценки качества работы алгоритма $a$ можно использовать следующий функционал:
[Q(a) = Exp_x Exp_ [y(x, eps) — a(x, X)]^2,]
- $X$ – обучающая выборка
- $x$ – точка из тестового множества
- $y = f(x) + eps$ – целевая зависимость, которую мы можем измерить с точностью до случайного шума $eps$
- $a(x, X)$ – значение алгоритма, обученного на выборке $X$, в точке $x$
- $Exp_x$ – среднее по всем тестовым точкам и $Exp_$ – среднее по всем обучающим выборкам $X$ и случайному шуму $eps$
Для $Q(a)$ существует разложение на три компоненты – шум, смещение и разброс. Это разложение называется bias-variance decomposition, и оно является одним из мощных средств для анализа работы ансамблей. О том, как его вывести, вы узнаете в соответствующей главе, а здесь мы приведём его формулировку.
Bias-variance decomposition . Существует представление $Q(a)$ в виде трёх компонент:
[Q(a) = Exp_x text_X^2 a(x, X) + Exp_x Var_X[a(x, X)] + sigma^2,]
[text_X a(x, X) = f(x) — Exp_X[a(x, X)]]
– смещение предсказания алгоритма в точке $x$, усреднённого по всем возможным обучающим выборкам, относительно истинной зависимости $f$,
[Var_X[a(x, X)] = Exp_X left[ a(x, X) — Exp_X[a(x, X)] right]^2]
– дисперсия (разброс) предсказаний алгоритма в зависимости от обучающей выборки $X$,
[sigma^2 = Exp_x Exp_eps[y(x, eps) — f(x)]^2]
– неустранимый шум в данных.
Раз нам известно, что ошибка алгоритма раскладывается на шум, смещение и разброс, можно подумать над способом сократить ошибку. Будет разумно попытаться сначала уменьшить одну из составляющих. Понятно, что с шумом уже ничего не сделать – это минимально возможная ошибка. Какую можно придумать процедуру, чтобы, например, сократить разброс, не увеличивая смещение?
Пример приходит из жизни древних греков. Если много древних греков соберутся на одном холме и проголосуют независимо друг от друга, то вместе они придут к разумному решению несмотря на то, что опыт каждого из них субъективен. Аналогом голосования в мире машинного обучения является бэггинг.
Бэггинг
Идея бэггинга (bagging, bootstrap aggregation) заключается в следующем. Пусть обучающая выборка состояла из $n$ объектов. Выберем из неё $n$ примеров равновероятно, с возвращением. Получим новую выборку $X^1$, в которой некоторых элементов исходной выборки не будет, а какие-то могут войти несколько раз. С помощью некоторого алгоритма $b$ обучим на этой выборке модель $b_1(x) = b(x, X^1)$. Повторим процедуру: сформируем вторую выборку $X^2$ из $n$ элементов с возвращением и с помощью того же алгоритма обучим на ней модель $b_2(x) = b(x, X^2)$. Повторив процедуру $k$ раз, получим $k$ моделей, обученных на $k$ выборках. Чтобы получить одно предсказание, усредним предсказания всех моделей:
Процесс генерации подвыборок с помощью семплирования с возвращением называется бутстрепом (bootstrap), а модели $b_1(x), ldots, b_k(x)$ часто называют базовыми алгоритмами (хотя, наверное, лучше было бы назвать их базовыми моделями). Модель $a(x)$ называется ансамблем этих моделей.
Посмотрим, что происходит с качеством предсказания при переходе от одной модели к ансамблю. Сначала убедимся, что смещение ансамбля не изменилось по сравнению со средним смещением отдельных моделей. Будем считать, что когда мы берём матожидание по всем обучающим выборкам $X$, то в эти выборки включены также все подвыборки, полученные бутстрепом.
[color_X a(x, X) => f(x) — Exp_X[a(x, X)] = f(x) — Exp_X left[ frac sum_^k b(x, X^i) right] =] [= f(x) — frac sum_^k Exp_X left[ b(x, X^i) right] = f(x) — frac sum_^k Exp_X left[ b(x, X) right] = f(x) — Exp_X b(x, X)] [= f(x) — Exp_X b(x, X) color_X b(x, X)>]
Получили, что смещение композиции равно смещению одного алгоритма. Теперь посмотрим, что происходит с разбросом.
[Var_X[a(x, X)] = Exp_X left[ a(x, X) — Exp_X[a(x, X)] right]^2 = \ = Exp_X left[ frac sum_^k b(x, X^i)- Exp_X left[ frac sum_^k b(x, X^i) right] right]^2 = \ = frac Exp_X left[ sum_^k left( b(x, X^i) — Exp_X b(x, X^i) right) right]^2 = \ = frac sum_^k Exp_X (b(x, X^i) — Exp_X b(x, X^i))^2 + \ + frac sum_ Exp_X left[ left( b(x, X^) — Exp_X b(x, X^) right) left( b(x, X^) — Exp_X b(x, X^) right) right] = \ = frac sum_^k Var_X b(x, X^i) + frac sum_ text left( b(x, X^), b(x, X^) right)]
Если предположить, что базовые алгоритмы некоррелированы, то:
Получилось, что в этом случае дисперсия композиции в $k$ раз меньше дисперсии отдельного алгоритма.
Пример: бэггинг над решающими деревьями
Пусть наша целевая зависимость $f(x)$ задаётся как
и к ней добавляется нормальный шум $eps sim mathcal(0, 9)$. Пример семпла из таких данных:

Попробуем посмотреть, как выглядят предсказания решающих деревьев глубины 7 и бэггинга над такими деревьями в зависимости от обучающей выборки. Обучим решающие деревья 100 раз на различных случайных семплах размера 20. Возьмём также бэггинг над 10 решающими деревьями глубины 7 в качестве базовых классификаторов и тоже 100 раз обучим его на случайных выборках размера 20. Если изобразить предсказания обученных моделей на каждой из 100 итераций, то можно увидеть примерно такую картину:

По этому рисунку видно, что общая дисперсия предсказаний в зависимости от обучающего множества у бэггинга значительно ниже, чем у отдельных деревьев, а в среднем предсказания деревьев и бэггинга не отличаются.
Чтобы подтвердить это наблюдение, мы можем изобразить смещение и разброс случайных деревьев и бэггинга в зависимости от максимальной глубины:

На графике видно, как значительно бэггинг сократил дисперсию. На самом деле, дисперсия уменьшилась практически в 10 раз, что равняется числу базовых алгоритмов ($k$), которые бэггинг использовал для предсказания:

Код для отрисовки картинок и подсчёта смещения и разброса можно найти в этом ноутбуке.
Random Forest
В предыдущем разделе мы сделали предположение, что базовые алгоритмы некоррелированы, и за счёт этого получили очень сильное уменьшение дисперсии у ансамбля относительно входящих в него базовых алгоритмов. Однако в реальной жизни добиться этого сложно: ведь базовые алгоритмы учили одну и ту же зависимость на пересекающихся выборках. Поэтому будет странно, если корреляция на самом деле нулевая. Но на практике оказывается, что строгое выполнение этого предположения не обязательно. Достаточно, чтобы алгоритмы были в некоторой степени не похожи друг на друга. На этом строится развитие идеи бэггинга для решающих деревьев — случайный лес.
Построим ансамбль алгоритмов, где базовый алгоритм — это решающее дерево. Будем строить по следующей схеме:
Для построения $i$-го дерева:
а. Сначала, как в обычном бэггинге, из обучающей выборки $X$ выбирается с возвращением случайная подвыборка $X^i$ того же размера, что и $X$.
Внимательный читатель мог заметить, что при построении случайного леса у специалиста по машинному обучению есть несколько степеней свободы. Давайте обсудим их подробнее.
Какая должна быть глубина деревьев в случайном лесе?
Ошибка модели (на которую мы можем повлиять) состоит из смещения и разброса. Разброс мы уменьшаем с помощью процедуры бэггинга. На смещение бэггинг не влияет, а хочется, чтобы у леса оно было небольшим. Поэтому смещение должно быть небольшим у самих деревьев, из которых строится ансамбль. У неглубоких деревьев малое число параметров, то есть дерево способно запомнить только верхнеуровневые статистики обучающей подвыборки. Они во всех подвыборках будут похожи, но будут не очень подробно описывать целевую зависимость. Поэтому при изменении обучающей подвыборки предсказание на тестовом объекте будет стабильным, но не точным (низкая дисперсия, высокое смещение). Наоборот, у глубоких деревьев нет проблем запомнить подвыборку подробно. Поэтому предсказание на тестовом объекте будет сильнее меняться в зависимости от обучающей подвыборки, зато в среднем будет близко к истине (высокая дисперсия, низкое смещение). Вывод: используем глубокие деревья.
Сколько признаков надо подавать дереву для обучения?
Ограничивая число признаков, которые используются в обучении одного дерева, мы также управляем качеством случайного леса. Чем больше признаков, тем больше корреляция между деревьями и тем меньше чувствуется эффект от ансамблирования. Чем меньше признаков, тем слабее сами деревья. Практическая рекомендация – брать корень из числа всех признаков для классификации и треть признаков для регрессии.
Сколько должно быть деревьев в случайном лесе?
Выше было показано, что увеличение числа элементарных алгоритмов в ансамбле не меняет смещения и уменьшает разброс. Так как число признаков и варианты подвыборок, на которых строятся деревья в случайном лесе, ограничены, уменьшать разброс до бесконечности не получится. Поэтому имеет смысл построить график ошибки от числа деревьев и ограничить размер леса в тот момент, когда ошибка перестанет значимо уменьшаться.
Вторым практическим ограничением на количество деревьев может быть время работы ансамбля. Однако есть положительное свойство случайного леса: случайный лес можно строить и применять параллельно, что сокращает время работы, если у нас есть несколько процессоров. Но процессоров, скорее всего, всё же сильно меньше числа деревьев, а сами деревья обычно глубокие. Поэтому на большом числе деревьев Random Forest может работать дольше желаемого и количество деревьев можно сократить, немного пожертвовав качеством.
Бустинг
Бустинг (boosting) – это ансамблевый метод, в котором так же, как и в методах выше, строится множество базовых алгоритмов из одного семейства, объединяющихся затем в более сильную модель. Отличие состоит в том, что в бэггинге и случайном лесе базовые алгоритмы учатся независимо и параллельно, а в бустинге – последовательно:

Каждый следующий базовый алгоритм в бустинге обучается так, чтобы уменьшить общую ошибку всех своих предшественников. Как следствие, итоговая композиция будет иметь меньшее смещение, чем каждый отдельный базовый алгоритм (хотя уменьшение разброса также может происходить). Поскольку основная цель бустинга – уменьшение смещения, в качестве базовых алгоритмов часто выбирают алгоритмы с высоким смещением и небольшим разбросом. Например, если в качестве базовых классификаторов выступают деревья, то их глубина должна быть небольшой – обычно не больше 2-3 уровней. Ещё одной важной причиной для выбора моделей с высоким смещением в качестве базовых является то, что такие модели, как правило, быстрее учатся. Это важно для их последовательного обучения, которое может стать очень дорогим по времени, если на каждой итерации будет учиться сложная модель. На текущий момент основным видом бустинга с точки зрения применения на практике является градиентный бустинг, о котором подробно рассказывается в соответствующей главе. Хотя случайный лес – мощный и достаточно простой для понимания и реализации алгоритм, на практике он чаще всего уступает градиентному бустингу. Поэтому градиентный бустинг сейчас – основное продакшн-решение, если работа происходит с табличными данными (в работе с однородными данными – картинками, текстами – доминируют нейросети).
Стекинг
Стекинг (stacking) – алгоритм ансамблирования, основные отличия которого от предыдущих состоят в следующем:
- он может использовать алгоритмы разного типа, а не только из какого-то фиксированного семейства. Например, в качестве базовых алгоритмов могут выступать метод ближайших соседей и линейная регрессия
- результаты базовых алгоритмов объединяются в один с помощью обучаемой мета-модели, а не с помощью какого-либо обычного способа агрегации (суммирования или усреднения)
Обучение стекинга проходит в несколько этапов:
- общая выборка разделяется на тренировочную и тестовую
- тренировочная выборка делится на $n$ фолдов. Затем эти фолды перебираются тем же способом, что используется при кросс-валидации: на каждом шаге фиксируются $(n — 1)$ фолдов для обучения базовых алгоритмов и один – для их предсказаний (вычисления мета-факторов). Такой подход нужен для того, чтобы можно было использовать всё тренировочное множество, и при этом базовые алгоритмы не переобучались
- на полученных мета-факторах обучается мета-модель. Кроме мета-факторов, она может принимать на вход и фичи из исходного датасета. Выбор зависит от решаемой задачи
Для получения мета-факторов на тестовом множестве базовые алгоритмы можно обучить на всём тренировочном множестве – переобучения в данном случае возникнуть не должно.
Если данных достаточно много, то можно просто разделить обучающие данные на две непересекающиеся части: ту, на которой учатся базовые алгортимы, и ту, на которой они делают свои предсказания и обучается мета-модель. Использование такого простого разбиения вместо кросс-валидации на тренировочных данных иногда называют блендингом (blending). Если данных совсем много, то тестовое множество тоже можно разделить на две части: тестовую и валидационную, и использовать последнюю для подбора гиперпараметров моделей-участников 🙂
С точки зрения смещения и разброса стекинг не имеет прямой интерпретации, так как не минимизирует напрямую ни ту, ни другую компоненту ошибки. Удачно работающий стекинг просто уменьшает ошибку, и, как следствие, её компоненты тоже будут убывать.
Методы сбора ансамблей алгоритмов машинного обучения: стекинг, бэггинг, бустинг
Из названия можно догадаться, что ансамбль — это просто несколько алгоритмов машинного обучения, собранных в единое целое. Такой подход часто используется для того, чтобы усилить «положительные качества» отдельно взятых алгоритмов, которые сами по себе могут работать слабо, а вот в группе — ансамбле давать хороший результат. При использовании ансамблевых методов алгоритмы учатся одновременно и могут исправлять ошибки друг друга. Типичными примерами методов, направленных на объединение «слабых» учеников в группу сильных являются (рис. 1):
Стекинг. Могут рассматриваться разнородные отдельно взятые модели. Существует мета-модель, которой на вход подаются базовые модели, а выходом является итоговый прогноз.
Бэггинг. Рассматриваются однородные модели, которые обучаются независимо и параллельно, а затем их результаты просто усредняются. Ярким представителем данного метода является случайный лес.
Бустинг. Рассматриваются однородные модели, которые обучаются последовательно, причем последующая модель должна исправлять ошибки предыдущей. Конечно, в качестве примера здесь сразу приходит на ум градиентный бустинг.
Три этих способа и будут детальнее рассмотрены далее.
Стекинг
Из трех вариантов стекинг является наименее популярным. Это можно проследить и по числу готовых реализаций данного метода в программных библиотеках. В том же sklearn.ensemble в python куда чаше используют AdaBoost, Bagging, GradientBoosting, чем тот же самый Stacking (хотя его реализация там тоже есть).
Стекинг выделяется двумя основными чертами: он может объединить в себе алгоритмы разной природы в качестве базовых. Например, взять метод опорных векторов (SVM), k-ближайших соседей (KNN) в качестве базовых и на основе их результатов обучить логистическую регрессию для классификации. Также стоит отметить непредсказуемость работы метамодели. Если в случае бэггинга и бустинга существует достаточно четкий и конкретный ансамблевый алгоритм (увидим далее), то здесь метамодель может с течением времени по-разному обучаться на входных данных.
Алгоритм обучения выглядит следующим образом (рис. 2):
Делим выборку на k фолдов (тот же смысл, что и в кросс-валидации).
Для объекта из выборки, который находится в k-ом фолде, делается предсказание слабыми алгоритмами, которые были обучены на k-1 фолдах. Этот процесс итеративен и происходит для каждого фолда.
Создается набор прогнозов слабых алгоритмов для каждого объекта выборки.
На сформированных низкоуровневыми алгоритмами прогнозах в итоге обучается метамодель.
Ссылки на библиотеки для использования метода приведены ниже:
Бэггинг
Бэггинг является уже более популярным подходом и зачастую при упоминании этого термина вспоминается алгоритм построения случайного леса, как наиболее типичного его представителя.
При данном методе базовые алгоритмы являются представителями одного и того же семейства, они обучаются параллельно и почти независимо друг от друга, а финальные результаты лишь агрегируются. Нам необходимо, чтобы на вход слабым алгоритмам подавались разные данные, а не один и тот же набор, ведь тогда результат базовых моделей будет идентичен и смысла в них не будет.
Для того, чтобы понять, каким образом исходный датасет делится для формирования входных выборок для слабых алгоритмов, используется понятие бутстрэпа. При использовании бутстрэпа из исходной выборки берется один случайный элемент, записывается в обучающую выборку, затем возвращается обратно. Так делается n раз, где n — желаемый размер обучающей выборки. Существует правило, что в обучающей выборке в итоге будет ~ 0.632*n разных объектов. Таким образом, должны сформироваться m обучающих выборок для m слабых алгоритмов.
Бутстрэп выборки являются в значительной степени независимыми. Отчасти поэтому и говорят, что базовые алгоритмы обучаются на выборках независимо.
Что касается агрегации выходов базовых алгоритмов, то в случае задачи классификации зачастую просто выбирается наиболее часто встречающийся класс, а в случае задачи регрессии выходы алгоритмов усредняются (рис. 3). В формуле под ai подразумеваются выходы базовых алгоритмов.

Рисунок 3
Общий процесс приведен на рисунке ниже (рис. 4):

Рисунок 4
Случайный лес
Бэггинг направлен на уменьшение разброса (дисперсии) в данных, и зачастую данный прием предстает в виде алгоритма случайного леса, где слабые модели — это довольно глубокие случайные деревья. Однако, при построении случайного леса используется еще один прием, такой как метод случайных подпространств. Мало того, что благодаря бутсрэпу выбираются некоторые объекты нашего датасета, так еще и выбирается случайное подмножество признаков. В итоге, наша условная матрица признаков уменьшается как по строкам, так и столбцам (рис. 5). Это помогает действительно снизить корреляцию между слабыми учениками.

Рисунок 5
Ссылки на библиотеки для использования метода приведены ниже:
Бустинг
В данном случае, модели уже не обучаются отдельно друг от друга, а каждая следующая правит ошибки предыдущей. То есть можно сказать, что если один слабый алгоритм не смог выявить какую-либо закономерность в данных, так как это было для него сложно, то следующая модель должна сделать это. Но из данного подхода вытекает недостаток: работу алгоритма трудно распараллелить из-за зависимости предыдущего и последующего шагов.
Бустинг направлен скорее на уменьшение смещения в данных, чем на снижение разброса в них. Поэтому в качестве базовых алгоритмов могут браться модели с достаточно высоким смещением, например, неглубокие случайные деревья.

Рисунок 6
Типичными представителями бустинга являются две модели: градиентный бустинг и AdaBoost. Обе по-разному решают одну и ту же оптимизационную задачу по поиску итоговой модели, представляющей собой взвешенную сумму слабых алгоритмов (рис. 6).
Градиентный бустинг использует типичный алгоритм градиентного спуска для решения задачи. Когда приходит время добавить новый слабый алгоритм в ансамбль делается следующее:
Находится оптимальный вектор сдвига, улучшающий предыдущий ансамбль алгоритмов.
Этот вектор сдвига является антиградиентом от функции ошибок работы предыдущего ансамбля моделей
Благодаря вектору сдвигов мы знаем, какие значения должны принимать объекты обучающей выборки
А поскольку нам надо найти очередной алгоритм в композиции, то находим тот, при использовании которого минимизируется отклонение ответов от истинных
Градиентный бустинг — это в своем роде обобщение AdaBoost, поэтому, возможно, зачастую его и изучают первым. На самом деле, два данных алгоритма следует рассматривать куда подробнее, выделяя отдельную статью.
Ссылки на библиотеки для использования метода приведены ниже:
Заключение
Таким образом, мы увидели, что для того, чтобы улучшить качество функционирования отдельно взятых моделей машинного обучения, существует ряд техник их объединения в ансамбли. Эти техники уже заложены в программные продукты и ими можно пользоваться, улучшая свое решение. Однако, с моей точки зрения, при решении задачи не стоит сразу же браться за них. Лучше сначала попробовать одну простую, отдельную модель, понять, как она функционирует на конкретных данных, а уже дальше использовать ансамбли.
Стекинг в машинном обучении
Укладка:
Стекинг — это способ объединения моделей классификации или регрессии, он состоит из двухуровневых оценок. Первый уровень состоит из всех базовых моделей, которые используются для прогнозирования выходных данных тестовых наборов данных. Второй уровень состоит из мета-классификатора или регрессора, который принимает все прогнозы базовых моделей в качестве входных данных и генерирует новые прогнозы.
Архитектура стекирования:
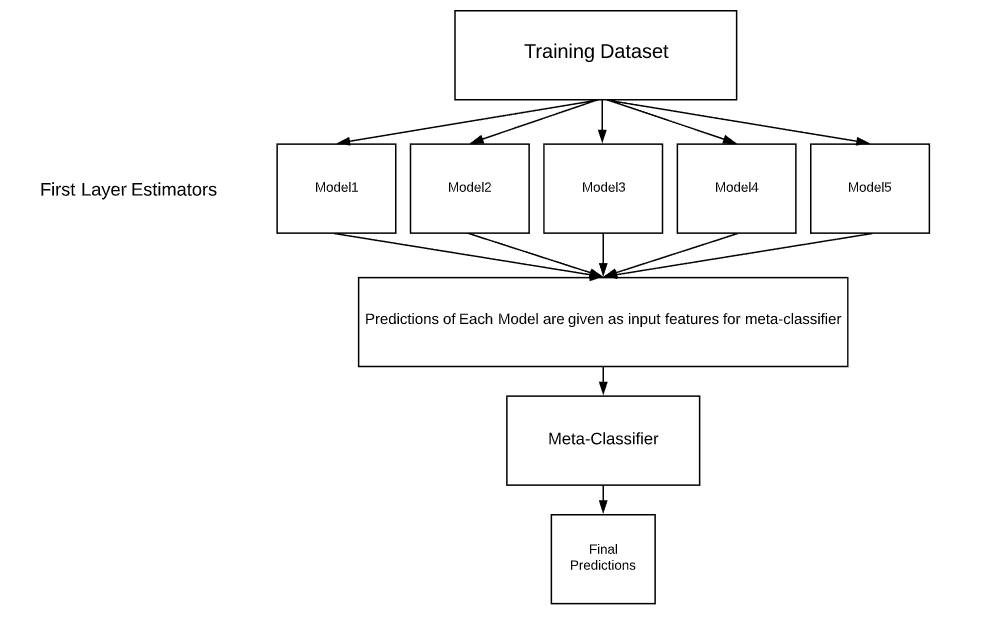
- Выбор функции
- Извлечение функций
- Визуализация
- Ансамбль
и многое другое.
В этой статье объясняется, как реализовать классификатор стекирования в наборе данных классификации.
Зачем складывать?
Большинство соревнований по машинному обучению и науке о данных выиграно с использованием составных моделей. Они могут улучшить существующую точность, которую демонстрируют отдельные модели. Мы можем получить большинство составных моделей, выбирая различные алгоритмы на первом уровне архитектуры, поскольку разные алгоритмы фиксируют разные тенденции в обучающих данных, объединение обеих моделей может дать лучшие и точные результаты.
Установка библиотек в систему:
pip install mlxtend
pip install pandas
pip install -U scikit-learn
Источник https://ml-handbook.ru/chapters/ensembles/intro
Источник https://habr.com/ru/post/561732/
Источник https://progler.ru/blog/steking-v-mashinnom-obuchenii